In this video we’ll learn How to use a mesh file to create a gazebo model. Different than URDF format, SDF is also used for entire robotic simulation environments.
Let’s go!
Links mentioned in the video and other useful links:
Robot Ignite Academy, the place to learn to program robots using only a web browser
ROS Development Studio (the environment used in the video), another powerful online tool for pushing your ROS learning in a practical way
In this video, you will learn two methods to move an element on the plane, ground level. This first one is using two prismatic joints working together to achieve this planar movement. The second is creating a custom plugin that sets the speeds of the model to move around the plane.
This post was written by Miguel A. Rodriguez and Ricardo Tellez
In this post we are going to see how to test different reinforcement learning (RL) algorithms from the OpenAI framework in the same robot trying to solve the same task. We are going to use the openai_ros package, which allows to change algorithms very easily and hence compare performances.
For the whole process, we are going to use the ROS Development Studio (ROSDS), which you can use for free. Also you can reproduce the results in your own local computer following these instructions.
The task to solve
We are going to use for this post the typical example in reinforcement learning of the cartpole. On the cartpole task, a pole mounted on top of a cart has to be balanced by the cart by moving left or right.
This problem is defined in the OpenAI Gym in the following links:
However, the OpenAi Gym just solves the problem on a 2D flat simulated environment with no real controllers for the cart and very limited physics simulation. That environment and its training looks something like the following video.
In this post, we are going to solve the same problem but using a 3D Gazebo simulation which includes full ROS controllers. The simulation includes physics and controllers behavior which makes the problem to solve even more complicated, but closer to reality.
Remember that the same thing we are doing in this post can be applied to ANY ROS BASED ROBOT.
The ROSject containing the simulation and pre-made code
We have created a ROSject containing the Gazebo simulation we are going to use, as well as some classes that interconnect the simulation to OpenAI. Those classes use the openai_ros package for easy definition of the RobotEnvironment (defines the connection of OpenAI to the simulated robot) and the TaskEnvironment (defines the task to be solved). This is already provided by the openai_ros package, so we’ll have to do nothing.
We provide all that work already done because in this post we want to concentrate only on comparing RL algorithms on the same robot and the same task.
You can get the code up and running on the ROSDS by getting this ROSject (click on the link to get the code). You can create a free account on ROSDS if you don’t have one. From the rest of tutorial we will assume you have the ROSject open in ROSDS (click on the link, then press Open ROSject on the ROSDS screen).
The Cartpole Simulation
You can launch the simulation inside the ROSDS going to the Simulations Drop Down Menu select Select Launch File and then select:
cartpole_description main.launch
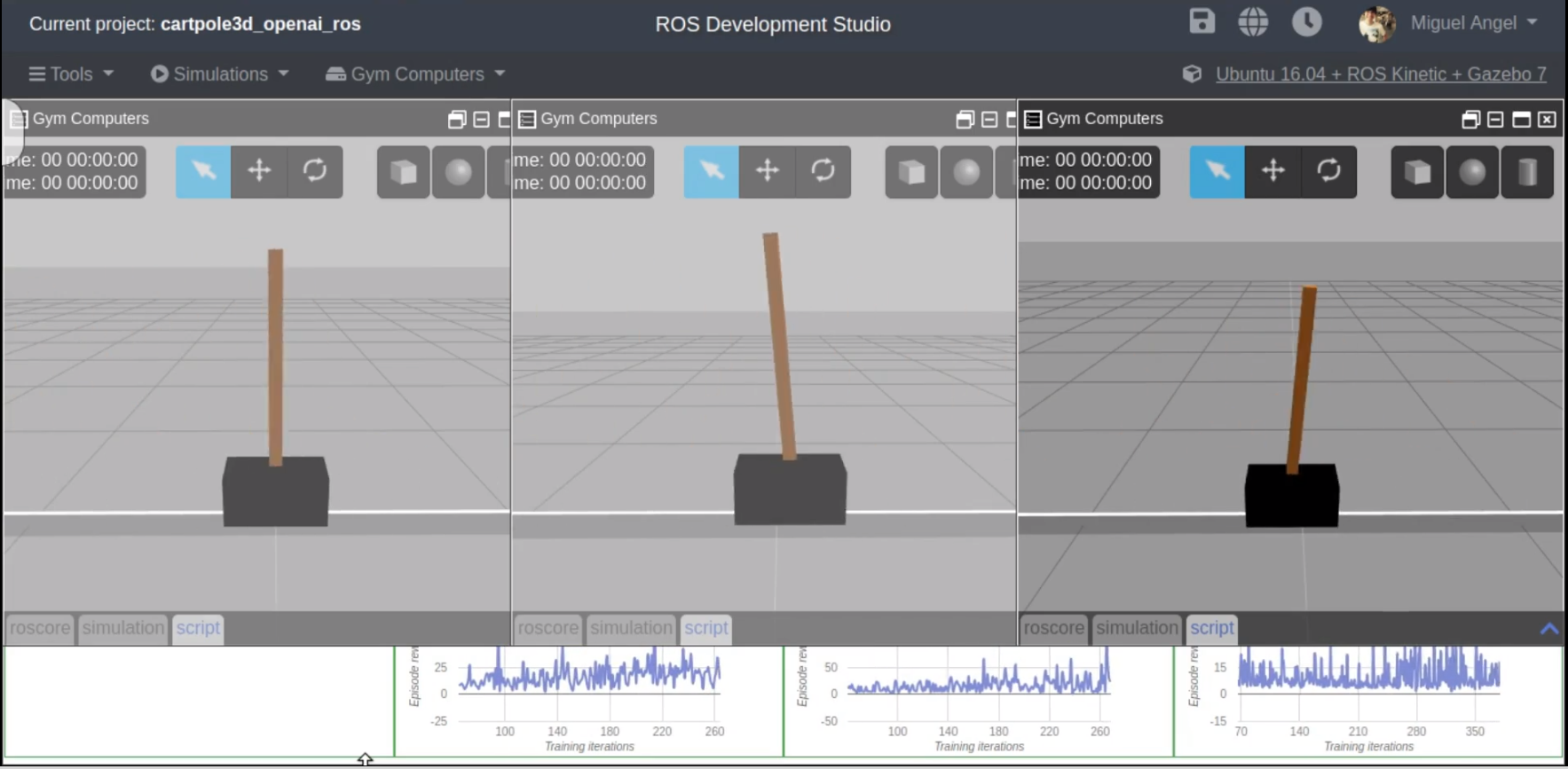
You should get something like this:
That is the simulation we are going to use. Remember that you have to have it launched for the rest of the tutorial.
The algorithms we are going to test
We took several of the best algorithms posted by the users on the OpenAI Gym website to solve the 2D cartpole system:
We adapted them for ROS and to use our Cartpole3D environment. For that we just had to do mainly 2 things:
Load the learning parameters from a yaml file instead of loading them from global variables. This allows us to change the values easily and fast. So we are going to create a yaml file for each algorithm that will be loaded before the algorithm is launched.
We have changed the OpenAI environment from the 2DCartpole provided by OpenAI (see video above) to the one provided by openai_ros package which interfaces with ROS and Gazebo.
Create the training code
First let’s create the ROS package that will contain everything
Create the ROS package for training
Let’s first create a ROS package where to put all the code we are going to develop. For that, open a shell (Tools->Shell) and type:
$ cd catkin_ws/src
$ catkin_create_pkg cartpole_tests rospy
Create the config files
Here you have an example of of the yaml file for the n1try. Its divided in two main parts:
Parameters for Reinforcement Learning algorithm: Values to needed by your learning algorithm, in this case would be n1try, but could be any.
Parameters for the RobotEnvironment and TaskEnvironment: These variables are used to tune the task and simulation during setup. These variables have already been set up for you to be optimum, and if you are asking where you would get them from the first place, you can just copy paste the ones in the git example for openai_ros, where you can find examples for all the supported simulations and tasks. https://bitbucket.org/theconstructcore/openai_examples_projects/src/master/
Now open the IDE of the ROSDS (Tools->IDE), navigate to the config directory and create there the config file with name cartpole_n1try_params.yaml
Then paste the following content to it and save it:
cartpole_v0: #namespace
#qlearn parameters
alpha: 0.01 # Learning Rate
alpha_decay: 0.01
gamma: 1.0 # future rewards value 0 none 1 a lot
epsilon: 1.0 # exploration, 0 none 1 a lot
epsilon_decay: 0.995 # how we reduse the exploration
epsilon_min: 0.01 # minimum value that epsilon can have
batch_size: 64 # maximum size of the batches sampled from memory
episodes_training: 1000
n_win_ticks: 250 # If the mean of rewards is bigger than this and have passed min_episodes, the task is considered finished
min_episodes: 100
#max_env_steps: None
monitor: True
quiet: False
# Cartpole3D environment variables
control_type: "velocity"
min_pole_angle: -0.7 #-23°
max_pole_angle: 0.7 #23°
max_base_velocity: 50
max_base_pose_x: 1.0
min_base_pose_x: -1.0
n_observations: 4 # Number of lasers to consider in the observations
n_actions: 2 # Number of actions used by algorithm and task
# those parameters are very important. They are affecting the learning experience
# They indicate how fast the control can be
# If the running step is too large, then there will be a long time between 2 ctrl commans
# If the pos_step is too large, then the changes in position will be very abrupt
running_step: 0.04 # amount of time the control will be executed
pos_step: 1.0 # increment in position/velocity/effort, depends on the control for each command
init_pos: 0.0 # Position in which the base will start
wait_time: 0.1 # Time to wait in the reset phases
Modify the learning algorithm for openai_ros
On the IDE create the following file on the scripts folder of your package: cartpole3D_n1try_algorithm_with_rosparams.py
#!/usr/bin/env python
import rospy
# Inspired by https://keon.io/deep-q-learning/
import random
import gym
import math
import numpy as np
from collections import deque
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import Adam
# import our training environment
from openai_ros.task_envs.cartpole_stay_up import stay_up
class DQNRobotSolver():
def __init__(self, environment_name, n_observations, n_actions, n_episodes=1000, n_win_ticks=195, min_episodes= 100, max_env_steps=None, gamma=1.0, epsilon=1.0, epsilon_min=0.01, epsilon_log_decay=0.995, alpha=0.01, alpha_decay=0.01, batch_size=64, monitor=False, quiet=False):
self.memory = deque(maxlen=100000)
self.env = gym.make(environment_name)
if monitor: self.env = gym.wrappers.Monitor(self.env, '../data/cartpole-1', force=True)
self.input_dim = n_observations
self.n_actions = n_actions
self.gamma = gamma
self.epsilon = epsilon
self.epsilon_min = epsilon_min
self.epsilon_decay = epsilon_log_decay
self.alpha = alpha
self.alpha_decay = alpha_decay
self.n_episodes = n_episodes
self.n_win_ticks = n_win_ticks
self.min_episodes = min_episodes
self.batch_size = batch_size
self.quiet = quiet
if max_env_steps is not None: self.env._max_episode_steps = max_env_steps
# Init model
self.model = Sequential()
self.model.add(Dense(24, input_dim=self.input_dim, activation='tanh'))
self.model.add(Dense(48, activation='tanh'))
self.model.add(Dense(self.n_actions, activation='linear'))
self.model.compile(loss='mse', optimizer=Adam(lr=self.alpha, decay=self.alpha_decay))
def remember(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))
def choose_action(self, state, epsilon):
return self.env.action_space.sample() if (np.random.random() <= epsilon) else np.argmax(self.model.predict(state)) def get_epsilon(self, t): return max(self.epsilon_min, min(self.epsilon, 1.0 - math.log10((t + 1) * self.epsilon_decay))) def preprocess_state(self, state): return np.reshape(state, [1, self.input_dim]) def replay(self, batch_size): x_batch, y_batch = [], [] minibatch = random.sample( self.memory, min(len(self.memory), batch_size)) for state, action, reward, next_state, done in minibatch: y_target = self.model.predict(state) y_target[0][action] = reward if done else reward + self.gamma * np.max(self.model.predict(next_state)[0]) x_batch.append(state[0]) y_batch.append(y_target[0]) self.model.fit(np.array(x_batch), np.array(y_batch), batch_size=len(x_batch), verbose=0) if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
def run(self):
rate = rospy.Rate(30)
scores = deque(maxlen=100)
for e in range(self.n_episodes):
init_state = self.env.reset()
state = self.preprocess_state(init_state)
done = False
i = 0
while not done:
# openai_ros doesnt support render for the moment
#self.env.render()
action = self.choose_action(state, self.get_epsilon(e))
next_state, reward, done, _ = self.env.step(action)
next_state = self.preprocess_state(next_state)
self.remember(state, action, reward, next_state, done)
state = next_state
i += 1
scores.append(i)
mean_score = np.mean(scores)
if mean_score >= self.n_win_ticks and e >= min_episodes:
if not self.quiet: print('Ran {} episodes. Solved after {} trials'.format(e, e - min_episodes))
return e - min_episodes
if e % 1 == 0 and not self.quiet:
print('[Episode {}] - Mean survival time over last {} episodes was {} ticks.'.format(e, min_episodes ,mean_score))
self.replay(self.batch_size)
if not self.quiet: print('Did not solve after {} episodes'.format(e))
return e
if __name__ == '__main__':
rospy.init_node('cartpole_n1try_algorithm', anonymous=True, log_level=rospy.FATAL)
environment_name = 'CartPoleStayUp-v0'
n_observations = rospy.get_param('/cartpole_v0/n_observations')
n_actions = rospy.get_param('/cartpole_v0/n_actions')
n_episodes = rospy.get_param('/cartpole_v0/episodes_training')
n_win_ticks = rospy.get_param('/cartpole_v0/n_win_ticks')
min_episodes = rospy.get_param('/cartpole_v0/min_episodes')
max_env_steps = None
gamma = rospy.get_param('/cartpole_v0/gamma')
epsilon = rospy.get_param('/cartpole_v0/epsilon')
epsilon_min = rospy.get_param('/cartpole_v0/epsilon_min')
epsilon_log_decay = rospy.get_param('/cartpole_v0/epsilon_decay')
alpha = rospy.get_param('/cartpole_v0/alpha')
alpha_decay = rospy.get_param('/cartpole_v0/alpha_decay')
batch_size = rospy.get_param('/cartpole_v0/batch_size')
monitor = rospy.get_param('/cartpole_v0/monitor')
quiet = rospy.get_param('/cartpole_v0/quiet')
agent = DQNRobotSolver( environment_name,
n_observations,
n_actions,
n_episodes,
n_win_ticks,
min_episodes,
max_env_steps,
gamma,
epsilon,
epsilon_min,
epsilon_log_decay,
alpha,
alpha_decay,
batch_size,
monitor,
quiet)
agent.run()
As you can see the main differences are the rosparam gets and the rosnode init. Also one element that has to be removed is the render method. Just because in Gazebo Render makes no sense, unless is for recording purposes, that will be supported in OpenAI_ROS RobotEnvironments in the future updates.
Create a launch file
And now you have to create a launch file thats loads those paramateres from the YAML file and starts up your script. Go to the launch directory and create the file start_training_n1try.launch
<?xml version="1.0" encoding="UTF-8"?>
<launch>
<rosparam command="load" file="$(find cartpole_tests)/config/cartpole_n1try_params.yaml" />
<!-- Launch the training system -->
<node pkg="cartpole_tests" name="cartpole3D_mbalunovic_algorithm" type="cartpole3D_n1try_algorithm_with_rosparams.py" output="screen"/>
</launch>
Adapt the algorithm to work with openai_ros TaskEnvironment
And this is the easiest part. You just have to change the name of the OpenAI Environment to load, and in this case import the openai_ros module. And that is, you change the 2D cartpole by the 3D gazebo realistic cartpole. That SIMPLE
This at the top in the import section:
# import our training environment
from openai_ros.task_envs.cartpole_stay_up import stay_up
And this line
self.env = gym.make('CartPole-v0')
To a different Task and its loaded through a variable of the class:
After a few seconds you should see the cartpole start moving and trying to learn.
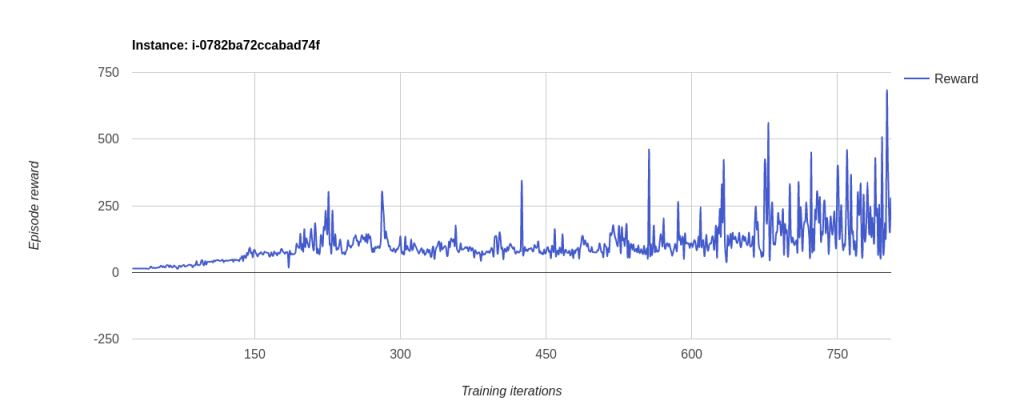
Results you may obtain
These are tests made with 1000 epsidoes maximum and it will stop the learning if:
We depleat our episodes ( more than 1000 )
We Get a Mean Episode Reward bigger than n_win_ticks and we have executed more than min_episodes number of episodes. In this case of n_win_ticks = 250 and min_episodes = 100. This is the reason why the 3D version stoped before the 1000 episodes had ended. Because the mean value of the episode rewards was bigger then 250. While the 2D had values not exceeding 200.
Note: to see the reward chart, got to Tools->OpenAI Reward Chart
How to change the learning algorithm
What if you want to change your algorithm for the same TaskEnvironment, like the CartPoleStayUp-v0? Well, with openai_ros is really fast. You just have to change the following:
Change the ROS Param YAML file loaded in the Launch file
Change the algorithm python script to be launched in the launch file to your new one.
Inside your new algorithm main script, place the same TaskEnvironment you had in the previous algorithm script.
For example lets say you need to change from the n1try to the mbalunovic or the ruippeixotog.
You will have to create new YAML files with the RL algorithm parameters you need, but with the same simulation parameters
For the mbalunovic algorithm
Create the config file cartpole_mbalunovic_params.yaml
cartpole_v0: #namespace
#qlearn parameters
state_size: 4 # number of elements in the state array from observations.
n_actions: 2 # Number of actions used by algorithm and task
learning_rate: 0.001
#num_epochs: 50
replay_memory_size: 1000
target_update_freq: 100
initial_random_action: 1
gamma: 0.99 # future rewards value, 0 none 1 a lot
epsilon_decay: 0.99 # how we reduse the exploration
done_episode_reward: -200 # Reward given when episode finishes before interations depleated.
batch_size: 32 # maximum size of the batches sampled from memory
max_iterations: 1000 # maximum iterations that an episode can have
episodes_training: 1000
# Environment variables
control_type: "velocity"
min_pole_angle: -0.7 #-23°
max_pole_angle: 0.7 #23°
max_base_velocity: 50
max_base_pose_x: 1.0
min_base_pose_x: -1.0
# those parameters are very important. They are affecting the learning experience
# They indicate how fast the control can be
# If the running step is too large, then there will be a long time between 2 ctrl commans
# If the pos_step is too large, then the changes in position will be very abrupt
running_step: 0.04 # amount of time the control will be executed
pos_step: 1.0 # increment in position/velocity/effort, depends on the control for each command
init_pos: 0.0 # Position in which the base will start
wait_time: 0.1 # Time to wait in the reset phases
Create the launch file start_training_mbalunovic.launch
<?xml version="1.0" encoding="UTF-8"?>
<launch>
<rosparam command="load" file="$(find cartpole_tests)/config/cartpole_mbalunovic_params.yaml" />
<!-- Launch the training system -->
<node pkg="cartpole_tests" name="cartpole3D_mbalunovic_algorithm" type="cartpole3D_mbalunovic_algorithm_with_rosparams.py" output="screen"/>
</launch>
Create the script file cartpole3D_mbalunovic_algorithm_with_rosparams.py (modification from original learning algorithm)
#!/usr/bin/env python
import rospy
import gym
import keras
import numpy as np
import random
from gym import wrappers
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import Adam
from collections import deque
# import our training environment
from openai_ros.task_envs.cartpole_stay_up import stay_up
class ReplayBuffer():
def __init__(self, max_size):
self.max_size = max_size
self.transitions = deque()
def add(self, observation, action, reward, observation2):
if len(self.transitions) > self.max_size:
self.transitions.popleft()
self.transitions.append((observation, action, reward, observation2))
def sample(self, count):
return random.sample(self.transitions, count)
def size(self):
return len(self.transitions)
def get_q(model, observation, state_size):
np_obs = np.reshape(observation, [-1, state_size])
return model.predict(np_obs)
def train(model, observations, targets, actions_dim, state_size):
np_obs = np.reshape(observations, [-1, state_size])
np_targets = np.reshape(targets, [-1, actions_dim])
#model.fit(np_obs, np_targets, epochs=1, verbose=0)
model.fit(np_obs, np_targets, nb_epoch=1, verbose=0)
def predict(model, observation, state_size):
np_obs = np.reshape(observation, [-1, state_size])
return model.predict(np_obs)
def get_model(state_size, learning_rate):
model = Sequential()
model.add(Dense(16, input_shape=(state_size, ), activation='relu'))
model.add(Dense(16, input_shape=(state_size,), activation='relu'))
model.add(Dense(2, activation='linear'))
model.compile(
optimizer=Adam(lr=learning_rate),
loss='mse',
metrics=[],
)
return model
def update_action(action_model, target_model, sample_transitions, actions_dim, state_size, gamma):
random.shuffle(sample_transitions)
batch_observations = []
batch_targets = []
for sample_transition in sample_transitions:
old_observation, action, reward, observation = sample_transition
targets = np.reshape(get_q(action_model, old_observation, state_size), actions_dim)
targets[action] = reward
if observation is not None:
predictions = predict(target_model, observation, state_size)
new_action = np.argmax(predictions)
targets[action] += gamma * predictions[0, new_action]
batch_observations.append(old_observation)
batch_targets.append(targets)
train(action_model, batch_observations, batch_targets, actions_dim, state_size)
def main():
state_size = rospy.get_param('/cartpole_v0/state_size')
action_size = rospy.get_param('/cartpole_v0/n_actions')
gamma = rospy.get_param('/cartpole_v0/gamma')
batch_size = rospy.get_param('/cartpole_v0/batch_size')
target_update_freq = rospy.get_param('/cartpole_v0/target_update_freq')
initial_random_action = rospy.get_param('/cartpole_v0/initial_random_action')
replay_memory_size = rospy.get_param('/cartpole_v0/replay_memory_size')
episodes_training = rospy.get_param('/cartpole_v0/episodes_training')
max_iterations = rospy.get_param('/cartpole_v0/max_iterations')
epsilon_decay = rospy.get_param('/cartpole_v0/max_iterations')
learning_rate = rospy.get_param('/cartpole_v0/learning_rate')
done_episode_reward = rospy.get_param('/cartpole_v0/done_episode_reward')
steps_until_reset = target_update_freq
random_action_probability = initial_random_action
# Initialize replay memory D to capacity N
replay = ReplayBuffer(replay_memory_size)
# Initialize action-value model with random weights
action_model = get_model(state_size, learning_rate)
env = gym.make('CartPoleStayUp-v0')
env = wrappers.Monitor(env, '/tmp/cartpole-experiment-1', force=True)
for episode in range(episodes_training):
observation = env.reset()
for iteration in range(max_iterations):
random_action_probability *= epsilon_decay
random_action_probability = max(random_action_probability, 0.1)
old_observation = observation
# We dont support render in openai_ros
"""
if episode % 1 == 0:
env.render()
"""
if np.random.random() < random_action_probability: action = np.random.choice(range(action_size)) else: q_values = get_q(action_model, observation, state_size) action = np.argmax(q_values) observation, reward, done, info = env.step(action) if done: print 'Episode {}, iterations: {}'.format( episode, iteration ) # print action_model.get_weights() # print target_model.get_weights() #print 'Game finished after {} iterations'.format(iteration) reward = done_episode_reward replay.add(old_observation, action, reward, None) break replay.add(old_observation, action, reward, observation) if replay.size() >= batch_size:
sample_transitions = replay.sample(batch_size)
update_action(action_model, action_model, sample_transitions, action_size, state_size, gamma)
steps_until_reset -= 1
if __name__ == "__main__":
rospy.init_node('cartpole_mbalunovic_algorithm', anonymous=True, log_level=rospy.FATAL)
main()
Create the config file cartpole_ruippeixotog_params.yaml
cartpole_v0: #namespace
#qlearn parameters
state_size: 4 # number of elements in the state array from observations.
n_actions: 2 # Number of actions used by algorithm and task
gamma: 0.95 # future rewards value, 0 none 1 a lot
epsilon: 1.0 # exploration, 0 none 1 a lot
epsilon_decay: 0.995 # how we reduse the exploration
epsilon_min: 0.1 # minimum value that epsilon can have
batch_size: 32 # maximum size of the batches sampled from memory
episodes_training: 1000
episodes_running: 500
#environment variables
control_type: "velocity"
min_pole_angle: -0.7 #-23°
max_pole_angle: 0.7 #23°
max_base_velocity: 50
max_base_pose_x: 1.0
min_base_pose_x: -1.0
# those parameters are very important. They are affecting the learning experience
# They indicate how fast the control can be
# If the running step is too large, then there will be a long time between 2 ctrl commans
# If the pos_step is too large, then the changes in position will be very abrupt
running_step: 0.04 # amount of time the control will be executed
pos_step: 1.0 # increment in position/velocity/effort, depends on the control for each command
init_pos: 0.0 # Position in which the base will start
wait_time: 0.1 # Time to wait in the reset phases
Create the launch file start_training_ruippeixotog.launch
<?xml version="1.0" encoding="UTF-8"?>
<launch>
<rosparam command="load" file="$(find cartpole_tests)/config/cartpole_ruippeixotog_params.yaml" />
<!-- Launch the training system -->
<node pkg="cartpole_tests" name="cartpole3D_ruippeixotog_algorithm" type="cartpole3D_ruippeixotog_algorithm.py" output="screen"/>
</launch>
Create the training script cartpole_ruippeixotog_algorithm.py
#!/usr/bin/env python
import rospy
import os
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import Adam
from gym_runner import GymRunner
from q_learning_agent import QLearningAgent
# import our training environment
from openai_ros.task_envs.cartpole_stay_up import stay_up
class CartPoleAgent(QLearningAgent):
def __init__(self):
state_size = rospy.get_param('/cartpole_v0/state_size')
action_size = rospy.get_param('/cartpole_v0/n_actions')
gamma = rospy.get_param('/cartpole_v0/gamma')
epsilon = rospy.get_param('/cartpole_v0/epsilon')
epsilon_decay = rospy.get_param('/cartpole_v0/epsilon_decay')
epsilon_min = rospy.get_param('/cartpole_v0/epsilon_min')
batch_size = rospy.get_param('/cartpole_v0/batch_size')
QLearningAgent.__init__(self,
state_size=state_size,
action_size=action_size,
gamma=gamma,
epsilon=epsilon,
epsilon_decay=epsilon_decay,
epsilon_min=epsilon_min,
batch_size=batch_size)
#super(CartPoleAgent, self).__init__(4, 2)
def build_model(self):
model = Sequential()
model.add(Dense(12, activation='relu', input_dim=4))
model.add(Dense(12, activation='relu'))
model.add(Dense(2))
model.compile(Adam(lr=0.001), 'mse')
# load the weights of the model if reusing previous training session
# model.load_weights("models/cartpole-v0.h5")
return model
if __name__ == "__main__":
rospy.init_node('cartpole3D_ruippeixotog_algorithm', anonymous=True, log_level=rospy.FATAL)
episodes_training = rospy.get_param('/cartpole_v0/episodes_training')
episodes_running = rospy.get_param('/cartpole_v0/episodes_running')
max_timesteps = rospy.get_param('/cartpole_v0/max_timesteps', 10000)
gym = GymRunner('CartPoleStayUp-v0', 'gymresults/cartpole-v0', max_timesteps)
agent = CartPoleAgent()
gym.train(agent, episodes_training, do_train=True, do_render=False, publish_reward=False)
gym.run(agent, episodes_running, do_train=False, do_render=False, publish_reward=False)
agent.model.save_weights("models/cartpole-v0.h5", overwrite=True)
#gym.close_and_upload(os.environ['API_KEY'])
Do the same process we did for the cartpole but for a Turtlebot robot that has to learn how to move around a round maze. Check the openai_ros package for the required RobotEnvironment and TaskEnvironment to use. You will see how easy it is to change what we have developed for the cartpole into a different robot and task!
Let’s see how to install Gazebo 9 simulator to work with your ROS system. We are going to see how to replace the default version of Gazebo that comes with the installation of ROS and if previously existing simulations work (or not) with this new version of the simulator.
How to install Gazebo ROS (Gazebo 9) in an existing ROS environment
I presume that you already have a ROS distribution in your system. If you do, you probably installed the version of Gazebo that came by default with that ROS distribution. If you check the documentation of Gazebo, you will see that the following table corresponds to the default versions of Gazebo that automatically install with ROS:
ROS Indigo: Gazebo 2.x
ROS Kinetic: Gazebo 7.x
ROS Lunar: Gazebo 7.x
Let’s see now, how can you proceed to change the default Gazebo version by the newest one (9.x as for 3rd May 2018).
First, uninstall the default Gazebo
If you want to install the latest version, you will have to remove first your default installed Gazebo (which was probably installed when you installed ROS). That is easy, because, independently of the ROS distro, the same command applies to all the distributions to remove the default Gazebo installation:
The integration of Gazebo with ROS is performed by means of the series of ros-<ROS_VERSION>-gazebo9 packages. The list of ROS – Gazebo packages that OpenRobotics is usually offering is the following (where in our case, we used ROS_VERSION=kinetic):
ros-kinetic-gazebo9-dev
ros-kinetic-gazebo9-plugins
ros-kinetic-gazebo9-ros-control
ros-kinetic-gazebo9-msgs
ros-kinetic-gazebo9-ros
ros-kinetic-gazebo9-ros-pkgs
Install Gazebo 9
A very simple command will do it:
$ sudo apt-get install ros-kinetic-gazebo9-*
That command will install all dependencies. To test if everything is properly working, just type:
$ gazebo
A window like the this should appear on your screen.
Gazebo 9 robot simulator start screen
[irp posts=”8825″ name=”Launching Husarion ROSbot navigation demo in Gazebo simulation”]
Testing Gazebo with a battery of ROS based simulations
So if you are reading this post is because you are interested in the combo Gazebo / ROS. And your next question should be: will this new version work with our previously working ROS based simulations? The answer to that question is… it depends. It depends for which Gazebo version your simulation was made, and which parts of Gazebo does that simulation use. We have done the following experiments with some of our simulations.
Testing with a robotic arm simulation
Let’s do a simple example: let’s launch a Wam arm robot, which includes several models, a kinect, a laser and an arm robot with joint controllers. The simulation was created for Gazebo 7.x
First, you need to create a catkin_ws:
$ mkdir -p ~/catkin_ws/src
$ cd ~/catkin_ws
$ catkin_make
You can clone and compile the Wam simulation from The Construct public simulations repo with the following commands:
$ cd ~/catkin_ws/src
$ git clone https://TheConstruct@bitbucket.org/theconstructcore/iri_wam.git -b kinetic
$ cd ..
$ catkin_make
$ roslaunch iri_wam_gazebo main.launch
The result is the simulation running just showing some warnings related to xacro namespace redefinitions.
inconsistent namespace redefinitions for xmlns:xacro:
old: http://ros.org/wiki/xacro
new: http://www.ros.org/wiki/xacro (/home/ricardo/catkin_ws/src/iri_wam/iri_wam_description/xacro/iri_wam_1.urdf.xacro)
That warning can be resolved by changing in all the affected files, the xacro definition from this:
xmlns:xacro="http://ros.org/wiki/xacro"
to this:
xmlns:xacro="http://www.ros.org/wiki/xacro"
There was no problem executing any of those. Bear in mind that it includes joint controllers as well as a couple of sensor plugins. So no modification was required in the simulation (remember, originally created for Gazebo 7.x).
Gazebo 9 simulation of the Wam robot with ROS
Testing with a wheeled robot simulation
Next simulation we tested was the Summit XL robot simulation by Robotnik. We used the following commands:
$ cd ~/catkin_ws/src
$ git clone https://TheConstruct@bitbucket.org/theconstructcore/summit_xl.git -b kinetic
$ cd ..
$ catkin_make
In this case, we also had no problem when launching the simulation with the following command:
$ roslaunch sumit_xl_course_basics main.launch
Summit XL robot simulation running in Gazebo 9
Testing with a full environment simulation
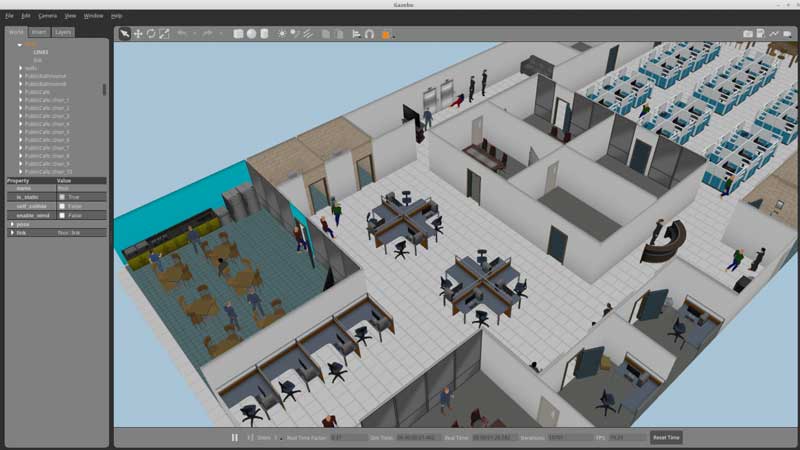
In this case, we decided to test a simulation created by the Gazebo team themselves, which they used for a competition and that was created for Gazebo 8. It is also an interesting simulation because includes a complete biped robot with several sensors, in a full office environment with people moving around, and plenty of stuff. Have a look at it here.
$ cd ~/catkin_ws/src
$ hg clone https://TheConstruct@bitbucket.org/osrf/servicesim
$ cd ..
$ catkin_make
$ roslaunch servicesim servicesim.launch
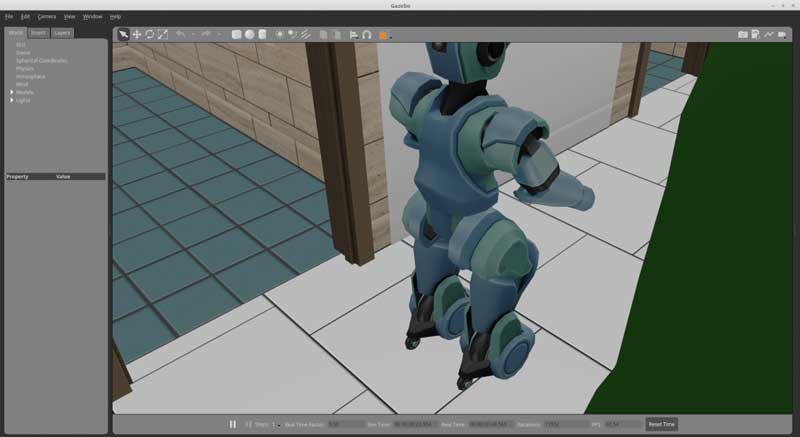
The simulation worked nicely off-the-shelf.
ServiceSim running in Gazebo 9
ServiceSim running in Gazebo 9
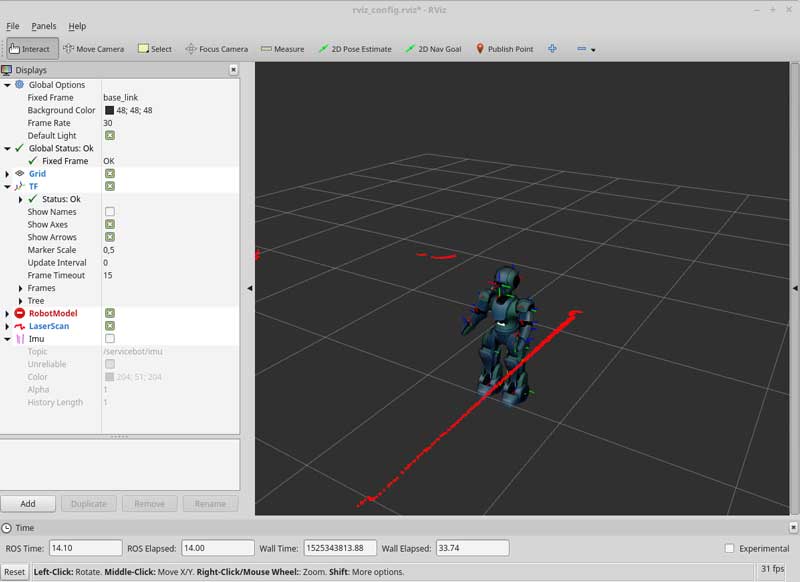
Rviz showing the data produced by ServiceSim in Gazebo 9
Problems when working with ROS with Gazebo 9
Gazebo is still and will always be a standalone program completely independent from ROS. This makes the work between them is not as smooth as it could be.
No ROS controllers provided
One of the problems I see with Gazebo 9 when working with ROS is that Gazebo provides a lot of interesting robot models through their Ignition Fuel library. However, none of the models includes the ROS controllers. So in case that you want to use the models for a ROS based situation, you need to create the controllers by yourself. One example of this case is the beautiful simulation of the autonomous car environmentcreated by the Gazebo team. The simulation is perfect for a work with autonomous cars, but the only support it has is for Gazebo topics.
Use of SDF format instead of URDF
An additional problem with the models is that they have been created in SDF format. SDF is the default format for creating models and whole simulations in Gazebo 9, but that format is not supported by ROS. This makes more difficult to use the models in Gazebo + ROS simualtions since ROS requires a URDF description of the model to show it on Rviz. (just in case you want to convert SDF models into URDF, check the following tutorial about it).
You may be thinking why to use then SDF instead of URDF for defining the simulations. One of the reasons for using SDF in Gazebo instead of URDF (as indicated by Louise Poubel in this interview of the ROS Developers Podcast) is that SDF overcomes some of the limitations of URDF, like for example the creation of closed loops in a robot model. URDF does not allow to create a robot that has a kinematic chain that splits into two at some point and then unite again. SDF handles that with easy. Watch this video to understand the problem:
Based on that, could it be that the most convenient solution would be to change ROS to support SDF instead of changing Gazebo to support URDF?
[irp posts=”9004″ name=”My Robotic Manipulator – Part #1 – Basic URDF and RViz”]
What about ROS plugins?
The ROS plugins for Gazebo 9 are the plugins that provide the access to the different sensors and actuators and other functionalities of the simulator through a ROS interface. ROS plugins packages are provided as a different set of ROS packages from the main Gazebo 9 distribution. Usually, those packages are provided some weeks after the new Gazebo version has been released. The good new is that those packages for Gazebo 9 are already available (good job Jose Luis Rivero 😉 and you already installed them at the beginning of this post.
If you where using standard plugins provided by ROS in your simulations, it is very likely that they will still work off-the-shelf. On the other side, if you have created your own plugins using the Gazebo API for that, chances are that they may not work and may need to adapt small changes done in the plugins API.
Conclusion
With Gazebo 9, the simulator reaches a very mature version were quite detailed simulations can be created. Just check for example the impressive simulation created by OSRF of an autonomous cars environment. Every new version we find new features, but more important than that, we find more stability (that is, less crashes).
If you want to know what features will be included in the future versions of Gazebo and when are they going to be released, just check the Gazebo roadmap.
![[Gazebo in 5 minutes] 005 – How to use a mesh file to create a gazebo model](https://www.theconstruct.ai/wp-content/uploads/2018/10/How-to-use-a-mesh-file-to-create-a-gazebo-model.png)
![[Gazebo in 5 minutes] 006 – How to use an image file as texture for gazebo model](https://www.theconstruct.ai/wp-content/uploads/2018/10/Gazebo-in-5-minutes-006-How-to-use-an-image-file-as-texture-for-gazebo-model.png)
![[Gazebo Q&A] 004 – How to create a Planar Moving Element in Gazebo ROS](https://www.theconstruct.ai/wp-content/uploads/2018/10/Gazebo-QA-004-How-to-create-a-Planar-Moving-Element-in-Gazebo-ROS.png)


![[Gazebo Q&A] 003 – How to spawn an SDF custom model in Gazebo with ROS](https://www.theconstruct.ai/wp-content/uploads/2018/10/Gazebo-QA-003-How-to-spawn-an-SDF-custom-model-in-Gazebo-with-ROS.png)