![[ROSDS] 008 – Use MoveIt with PR2 robot in ROS Kinetic Gazebo Easy Guide](https://www.theconstruct.ai/wp-content/uploads/2019/01/Use-MoveIt-with-PR2-robot-in-ROS-Kinetic-Gazebo-Easy-Guide.jpg)
[ROSDS] 008 – Use MoveIt with PR2 robot in ROS Kinetic Gazebo Easy Guide
What we are going to learn
- Learn the basics of how to use MoveIt! to move the end effectors of both arms of the PR2 robot simulation in Gazebo.
List of resources used in this post
- The ROSject of the project wit the simulation and the ROS Packages.
https://rds.theconstructsim.com/tc_projects/use_project_share_link/9cc5c592-b654-4ad3-ae65-a435642b84de - The Git to the code used in the ROSject: https://bitbucket.org/theconstructcore/pr2/src/master/
- Here you have the link to RobotIgniteAcademy courses: https://goo.gl/EiSJ9J
Launching the simulation
When you click in the ROSject link, you will get a copy of the ROSject. You can then download it if you want to use it on our local computer, or you can just click Open to have it opened in ROSDS.
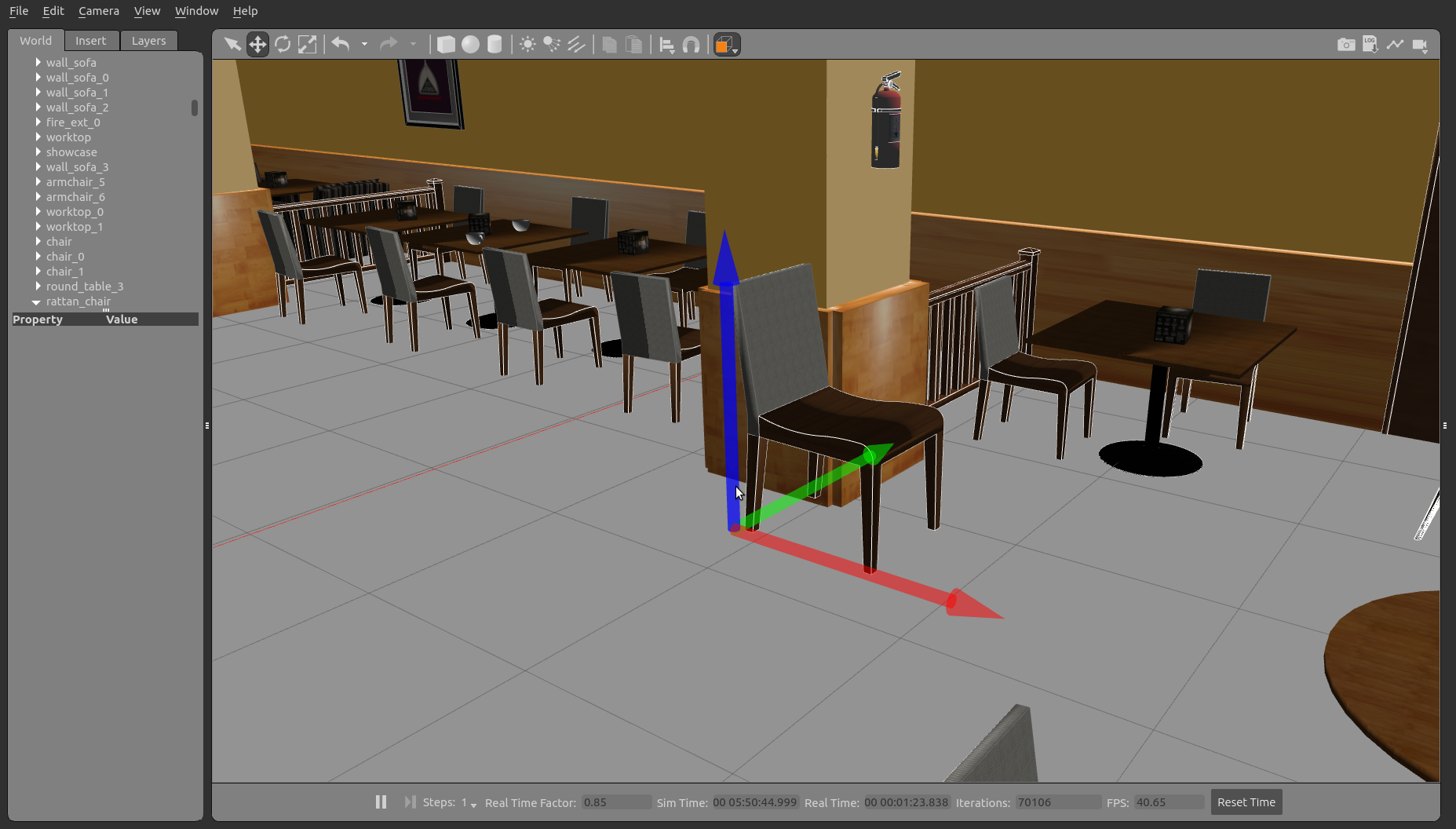
Once you have it open, you launch the simulation through the Simulation -> Select a launch file button. Then, in the pr2_description package select the pick_place_project_mod.launch launch file.
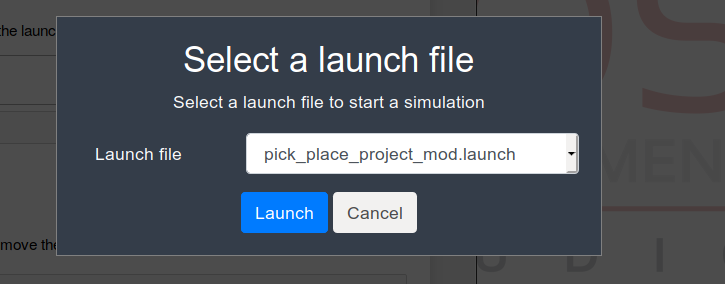
pr2_description pick_and_place_project_mod.launch in ROSDS
The following simulation should appear in your screen after a few seconds:
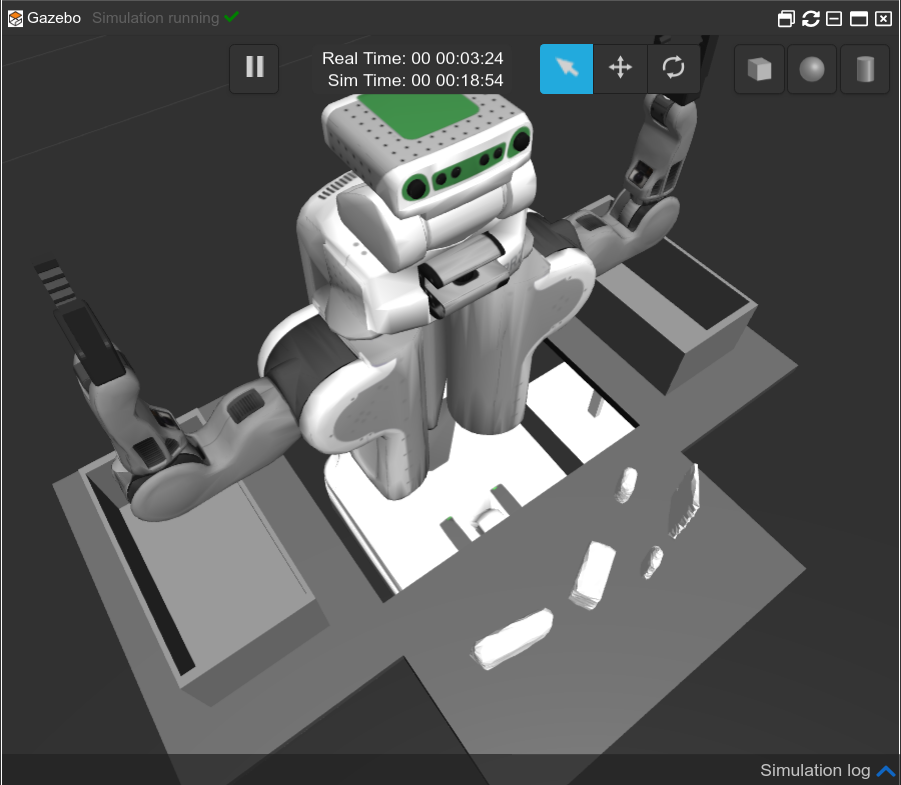
pr2 robot up and running in ROSDS
Launch a Moveit Arms test
Now that the simulation is running, you can run the demo that moves the arms of the robot using MoveIt!. For that, you can open a web shell (Tools->shell) and then type the following command:
$ rosrun pr2_description pr2_movit_demo.py

pr2_moving arms in ROSDS
That file used to move the arms is on pr2/pr2_description/demos/pr2_moveit_demo.py and it has the following content:
#!/usr/bin/env python
# TODO: This is in construction based on the pr2 moveit
import rospy
import sys
import moveit_commander
import moveit_msgs.msg
import geometry_msgs.msg
import trajectory_msgs.msg
import copy
import actionlib
import rospy
from math import sin, cos
from moveit_python import (MoveGroupInterface,
PlanningSceneInterface,
PickPlaceInterface)
from moveit_python.geometry import rotate_pose_msg_by_euler_angles
from control_msgs.msg import FollowJointTrajectoryAction, FollowJointTrajectoryGoal
from control_msgs.msg import PointHeadAction, PointHeadGoal
from control_msgs.msg import GripperCommandAction, GripperCommandGoal
from move_base_msgs.msg import MoveBaseAction, MoveBaseGoal
from trajectory_msgs.msg import JointTrajectory, JointTrajectoryPoint
from pr2_description.srv import Pr2Move, Pr2MoveResponse, Pr2MoveRequest
from geometry_msgs.msg import Pose
class MovePR2(object):
def __init__(self):
rospy.loginfo("In Move PR2 Class init...")
pr2_move_service = rospy.Service('/pr2_move_service', Pr2Move , self.move_callback)
# MOVEIT
moveit_commander.roscpp_initialize(sys.argv)
rospy.logdebug("moveit_commander initialised...")
rospy.logdebug("Starting Robot Commander...")
self.robot = moveit_commander.RobotCommander()
rospy.logdebug("Starting Robot Commander...DONE")
self.scene = moveit_commander.PlanningSceneInterface()
rospy.logdebug("PlanningSceneInterface initialised...DONE")
"""
MoveIt Groups For now:
right_arm
left_arm
right_gripper
left_gripper
"""
self.moveit_groups_dict = {}
self.group_right_arm = moveit_commander.MoveGroupCommander("right_arm")
rospy.logdebug("MoveGroupCommander for right_arm initialised...DONE")
# TODO: Add support for these new groups
self.group_left_arm = moveit_commander.MoveGroupCommander("left_arm")
rospy.logdebug("MoveGroupCommander for left_arm initialised...DONE")
self.group_right_gripper = moveit_commander.MoveGroupCommander("right_gripper")
rospy.logdebug("MoveGroupCommander for right_gripper initialised...DONE")
self.group_left_gripper = moveit_commander.MoveGroupCommander("left_gripper")
rospy.logdebug("MoveGroupCommander for left_gripper initialised...DONE")
# Fill in The dictionary
self.moveit_groups_dict = {"right_arm": self.group_right_arm,
"left_arm": self.group_left_arm,
"right_gripper": self.group_right_gripper,
"left_gripper": self.group_left_gripper
}
rospy.loginfo("PR2 ready to move!")
def move_callback(self, request):
move_response = Pr2MoveResponse()
pose_requested = request.pose
joints_array_requested = request.joints_array
movement_type_requested = request.movement_type.data
if movement_type_requested == "TCP":
move_response.success = self.ee_traj(pose_requested)
elif movement_type_requested == "JOINTS":
move_response.success = self.joint_traj(joints_array_requested)
else:
rospy.logerr("Asked for non supported movement type==>"+str(movement_type_requested))
return move_response.success
def ee_traj(self, pose, group_name = "right_arm"):
result = False
if group_name in self.moveit_groups_dict:
moveit_grup_obj = self.moveit_groups_dict[group_name]
pose_frame = moveit_grup_obj.get_pose_reference_frame()
rospy.loginfo("pose_frame==>"+str(pose_frame))
if pose_frame != "/world":
new_reference_frame = "/world"
moveit_grup_obj.set_pose_reference_frame(new_reference_frame)
pose_frame = moveit_grup_obj.get_pose_reference_frame()
rospy.logerr("pose_frame==>"+str(pose_frame))
else:
rospy.logwarn("pose_frame OK, ==>"+str(pose_frame))
moveit_grup_obj.set_pose_target(pose)
result = self.execute_trajectory(moveit_grup_obj)
else:
rospy.logerr("MoveitGroup Requested doesnt exist==>"+str(group_name))
return result
def joint_traj(self, positions_array, group_name = "right_arm"):
result = False
if group_name in self.moveit_groups_dict:
moveit_grup_obj = self.moveit_groups_dict[group_name]
self.group_variable_values = moveit_grup_obj.get_current_joint_values()
rospy.logdebug("Group Vars:")
rospy.logdebug(self.group_variable_values)
rospy.logdebug("Point:")
rospy.logdebug(positions_array)
self.group_variable_values[0] = positions_array[0]
self.group_variable_values[1] = positions_array[1]
self.group_variable_values[2] = positions_array[2]
self.group_variable_values[3] = positions_array[3]
self.group_variable_values[4] = positions_array[4]
self.group_variable_values[5] = positions_array[5]
self.group_variable_values[6] = positions_array[6]
moveit_grup_obj.set_joint_value_target(self.group_variable_values)
result = self.execute_trajectory()
else:
rospy.logerr("MoveitGroup Requested doesnt exist==>"+str(group_name))
return result
def execute_trajectory(self, moveit_grup_obj):
self.plan = moveit_grup_obj.plan()
result = moveit_grup_obj.go(wait=True)
return result
def ee_pose(self, group_name = "right_arm"):
gripper_pose = None
if group_name in self.moveit_groups_dict:
moveit_grup_obj = self.moveit_groups_dict[group_name]
gripper_pose = moveit_grup_obj.get_current_pose()
rospy.logdebug("EE POSE==>"+str(gripper_pose))
else:
rospy.logerr("MoveitGroup Requested doesnt exist==>"+str(group_name))
return gripper_pose
def ee_rpy(self, group_name = "right_arm"):
gripper_rpy = None
if group_name in self.moveit_groups_dict:
gripper_rpy = self.group_right_arm.get_current_rpy()
rospy.logdebug("EE POSE==>"+str(gripper_rpy))
else:
rospy.logerr("MoveitGroup Requested doesnt exist==>"+str(group_name))
return gripper_rpy
def Test1_get_ee_pose():
move_pr2_obj = MovePR2()
move_pr2_obj.ee_pose()
rospy.spin()
def Test2_get_ee_rpy():
move_pr2_obj = MovePR2()
move_pr2_obj.ee_rpy()
rospy.spin()
def Test3_move_rightarm():
move_pr2_obj = MovePR2()
"""
InitPose:
position:
x: -0.0377754141785
y: -0.662459908134
z: 1.29999835891
orientation:
x: -0.512647205153
y: -0.526060636653
z: -0.473572200618
w: 0.485986029032
"""
end_effector_pose = Pose()
"""
Bicuit pose
pick_pose:
position: {x: 0.56, y: -0.24, z: 0.97}
orientation: {x: 0.5, y: 0.5, z: -0.5, w: 0.5}
"""
# Prepick pose Biscuits
end_effector_pose.position.x = 0.56
end_effector_pose.position.y = -0.24
end_effector_pose.position.z = 0.97
end_effector_pose.orientation.x = 0.5
end_effector_pose.orientation.y = 0.5
end_effector_pose.orientation.z = -0.5
end_effector_pose.orientation.w = 0.5
move_response = Pr2MoveResponse()
move_response.success = move_pr2_obj.ee_traj( pose = end_effector_pose,
group_name = "right_arm")
rospy.spin()
def Test4_move_leftarm():
move_pr2_obj = MovePR2()
"""
Initila Pose
position:
x: -0.0377399293174
y: 0.662381672407
z: 1.30002783644
orientation:
x: 0.512720601674
y: -0.526108503211
z: 0.473527342165
w: 0.485900487437
"""
end_effector_pose = Pose()
"""
Soap2 pose
pick_pose:
position: {x: 0.46, y: 0.23, z: 0.95}
orientation: {x: 0.293, y: 0.643, z: -0.293, w: 0.643}
"""
# Init pose
end_effector_pose.position.x = -0.0377399293174
end_effector_pose.position.y = 0.662381672407
end_effector_pose.position.z = 1.30002783644
end_effector_pose.orientation.x = 0.512720601674
end_effector_pose.orientation.y = -0.526108503211
end_effector_pose.orientation.z = 0.473527342165
end_effector_pose.orientation.w = 0.485900487437
move_response = Pr2MoveResponse()
move_response.success = move_pr2_obj.ee_traj( pose = end_effector_pose,
group_name = "left_arm")
# Init pose
# Prepick pose Biscuits
end_effector_pose.position.x = 0.56
end_effector_pose.position.y = 0.24
end_effector_pose.position.z = 0.97
end_effector_pose.orientation.x = 0.5
end_effector_pose.orientation.y = 0.5
end_effector_pose.orientation.z = -0.5
end_effector_pose.orientation.w = 0.5
move_response = Pr2MoveResponse()
move_response.success = move_pr2_obj.ee_traj( pose = end_effector_pose,
group_name = "left_arm")
rospy.spin()
def Test5_get_ee_pose_leftarm():
move_pr2_obj = MovePR2()
move_pr2_obj.ee_pose(group_name = "left_arm")
rospy.spin()
def Test6_move_left_and_right_arm():
move_pr2_obj = MovePR2()
end_effector_pose = Pose()
# Prepick pose Biscuits
end_effector_pose.position.x = 0.56
end_effector_pose.position.y = -0.24
end_effector_pose.position.z = 0.97
end_effector_pose.orientation.x = 0.5
end_effector_pose.orientation.y = 0.5
end_effector_pose.orientation.z = -0.5
end_effector_pose.orientation.w = 0.5
move_response = Pr2MoveResponse()
move_response.success = move_pr2_obj.ee_traj( pose = end_effector_pose,
group_name = "right_arm")
# Init pose
# Prepick pose Biscuits
end_effector_pose.position.x = 0.56
end_effector_pose.position.y = 0.24
end_effector_pose.position.z = 0.97
end_effector_pose.orientation.x = 0.5
end_effector_pose.orientation.y = 0.5
end_effector_pose.orientation.z = -0.5
end_effector_pose.orientation.w = 0.5
move_response = Pr2MoveResponse()
move_response.success = move_pr2_obj.ee_traj( pose = end_effector_pose,
group_name = "left_arm")
rospy.spin()
if __name__ == '__main__':
rospy.init_node('pr2_move_node', anonymous=True, log_level=rospy.DEBUG)
Test6_move_left_and_right_arm()
Opening MoveIt! Setup Assistant
To get data from the pr2_moveit package, the best way is to access it through the Moveit Wizard:
roslaunch moveit_setup_assistant setup_assistant.launch
Once launched that command, in order to see the window of the setup assistant, you need to open the Graphical Tools by clicking (Tools->Graphical Tools):
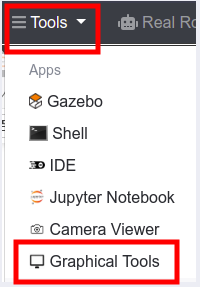
Launching Graphical Tools in ROSDS
then the Setup Assistant will appear:
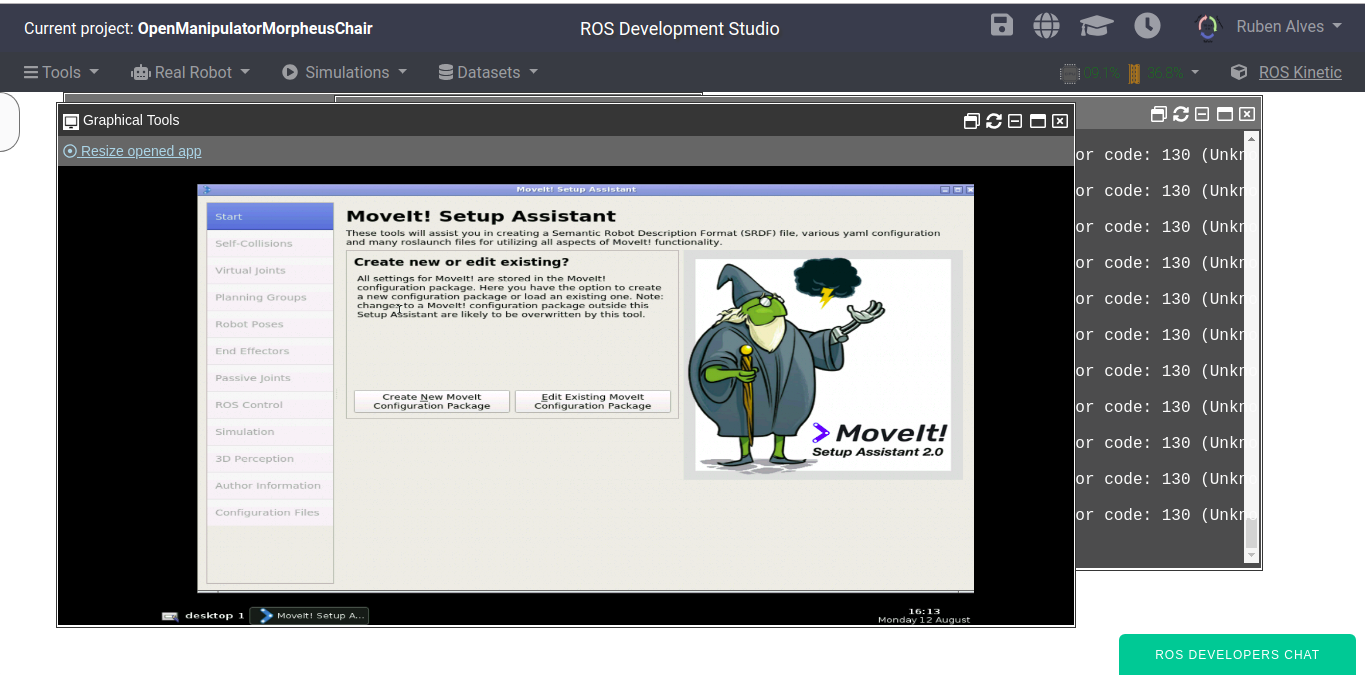
To better understand how to setup MoveIt!, now we recommend you check the video (https://youtu.be/wNGIrYtidME?t=277) that contains detailed explanation. In the video, we also give a detailed explanation about the file used to move the arms.
Youtube Video
So this is today’s post. Remember that we have the live version of this post on YouTube. If you liked the content, please consider subscribing to our youtube channel. We are publishing new content ~every day.
Keep pushing your ROS Learning.
















![[ROS Projects] OpenAI with Moving Cube Robot in Gazebo Step-by-Step #Part5](https://www.theconstruct.ai/wp-content/uploads/2018/07/ROS-Projects-OpenAI-with-Moving-Cube-Robot-in-Gazebo-Step-by-Step-Part5.png)