
Machine Learning with OpenAI Gym on ROS Development Studio
Imagine how easy it would be to learn skating, if only it doesn’t hurt everytime you fall. Unfortunately, we, humans, don’t have that option. Robots, however, can now “learn” their skills on a simulation platform without being afraid of crashing into a wall. Yes, “it learns“! This is possible with the reinforcement learning algorithms provided by OpenAI Gym and the ROS Development Studio.
You can now train your robot to navigate through an environment filled with obstacles just based on the sensor inputs, with the help of OpenAI Gym. In April 2016, OpenAI introduced “Gym”, a platform for developing and comparing reinforcement learning algorithms. Reinforcement learning is an area of machine learning that allows an intelligent agent (for example, robot) to learn the best behaviors in an environment by trial-and-error. The agent takes actions in an environment so as to maximize its rewards. We have deployed the gym_gazebo package from Erle Robotics S.L. in the ROS Development Studio. It enables the users to test their reinforcement learning for their robots in Gazebo.
- How to Train your Robot

Robot training to navigate through an environment with obstacles
In this example we will be seeing how a turtlebot is able to learn navigating through an environment without hitting an obstacle. The turtlebot will use a reinforcement learning method known as Q-learning.
There are four environments already available for the user to test their simulations with. These environments can be launched using the respective launch files:
- GazeboCircuitTurtlebotLidar_v0.launch
- GazeboCircuit2TurtlebotLidar_v0.launch
- GazeboRoundTurtlebotLidar_v0.launch
- GazeboMazeTurtlebotLidar_v0.launch
The images of the different environments are given below:
Circuit |
Circuit2 |
Round |
Maze |
The user is requested to try out the existing environment before developing their own environments for training the robot. An environment is where the robot’s possible actions and rewards are defined. For example, in the available environments, there are three possible actions for the Turtlebot robot:
– Forward ( with a reward of 5 points)
– Left ( with a reward of 1 point)
– Right ( with a reward of 1 point)
If it collides into the walls, then the training episode ends (with a penalty of 200 points). The turtlebot has to learn to navigate through the environment, based on the rewards obtained from different episodes. This can be achieved using the Q-learning algorithm. Let us see, how it can be done using the ROS Development Studio.
- Using the ROS Development Studio for training the robot
First, we have to set the path in the jupyter-notebook as given below:
import sys
sys.path.append("/usr/local/lib/python2.7/dist-packages/")
sys.path.append("/home/ubuntu/gym-gazebo")
sys.path.append("/home/user/catkin_ws/src/gym_construct/src")
%matplotlib inline
The python scripts in the folder gym_construct/src/ help us simulate the reinforcement learning techniques for a Turtlebot. Currently, the number of episodes has been set to 20.
Feel free to increase the number of episodes in the python scripts (usually up to 5000) to actually train the robot to navigate the environment completely.Run the only the script corresponding to the environment:
Run the python corresponding to the environment:
## Circuit-2 Environment --> Q-learning
%run /home/user/catkin_ws/src/gym_construct/src/circuit2_turtlebot_lidar_qlearn.py
The robot undergoes several training episodes and each of these episodes are rewarded based on the number of steps taken by the robot before hitting the environment. We will be able to see that the robot incrementally increases its rewards over time compared to its previous versions. With a very large number of episodes, the robot will learn to navigate the environment without hitting the obstacle.
- Plotting the learning curve of the robot
The machine learning algorithm generates the output files in the output directory specified in the python script file. In order to plot the curve, we run the display_plot.py. But before that, don’t forget to restart the kernel and set the path once again.
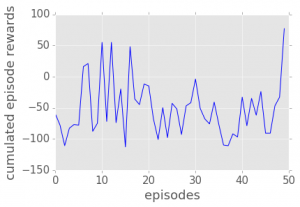
As the number of episodes increases, we will see that the robot’s mean rewards also increases. The user can choose his own robot, environments, action and rewards for testing his reinforcement learning algorithms in OpenAI Gym and RDS. Watch the video below for more on this.
- Video describing the procedure to run OpenAI Gym on RDS
I hope you were able to follow the tutorial. So, that’s all folks. It’s now up to you to develop and test reinforcement learning algorithms in OpenAI Gym and RDS.
Have fun training your robot!
—–
Credits
| Machine Learning Toolkit from OpenAI – (https://gym.openai.com/) | |
| Simulation package from ErleRobotics – gazebo_gym (https://github.com/erlerobot/gym-gazebo/) |
Deployed in RDS by:
- Vengatesan Govindaraju ( LinkedIn Profile )
- Miguel Angel Rodriguez ( LinkedIn Profile )
***

Podcast: Play in new window | Download | Embed
SUBSCRIBE NOW: RSS